
HDFS – Why another file system?
February 6, 2017HDFS Architecture
February 13, 2017In the HDFS – Why another filesytem post, we got ourselves introduced about HDFS its time to try some HDFS commands. You are probably thinking why are we not talking about Namenode, Datanode etc. HDFS Architecture is covered here.
You can get access to our free Hadoop cluster to try the commands in this post. Before you go on reading this post, please note that this post is from our free course named Hadoop Starter Kit. It is a free introductory course on Hadoop and it is 100% free. Click here to enroll to Hadoop Starter Kit. You will also get free access to our 3 node Hadoop cluster hosted on Amazon Web Services (AWS) – also free !
We ended the last HDFS – Why another filesytem post looking at how HDFS is different from the local filesystem. Let’s continue on that discussion. Here are some of the well known commands to work with your local filesystem in linux. You would use mkdir to create a directory, cp to copy, ls to list the contents of a directory, rm to delete etc.
Simple HDFS commands
All HDFS commands start with hadoop fs. Regular ls command on root directory will bring the files from root directory in the local file sytem. hadoop fs -ls / list the files from the root directory in HDFS. As you can see the output of local filesystem listing is different from what you see from the HDFS listing. That is excepted. Why? Because HDFS has a global view of the files in your hadoop cluster across all nodes where as the local filesystem can only view or list the files available locally.

Now let’s try the same 2 commands on another node in the cluster and see how it looks. The output of hdfs listing is same on both nodes. same number of files and diretories and same content. Look at the local filesystem listing on both nodes. The number of files and diretories are not the same also the content is different. This proves that HDFS has a unified global view across all the nodes in the cluster where as the local file sytem does not have a global unified view and its view is limitied to the local file sytem.
Here is the screenshot for directory listing from another node (Slave 2) of Hadoop cluster.
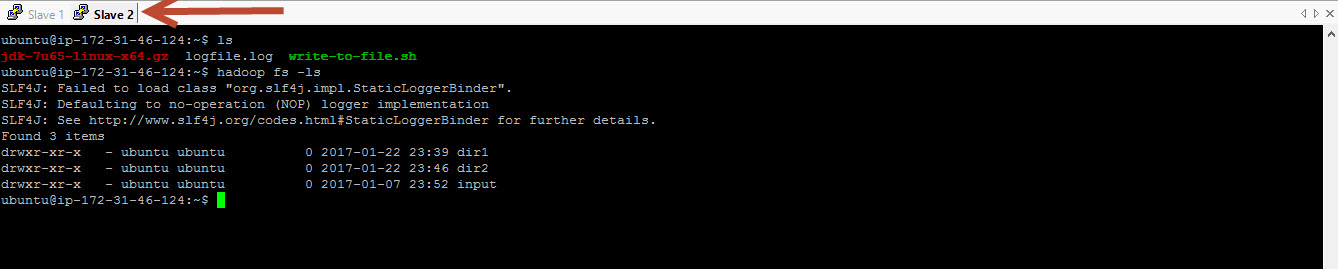
Lets go back to our node. Lets look at user’s home diretory. The home directory in your local file sytem will be /home/<username>. Where as the home directory in HDFS is configured to use /user/<username>. So in our case since I am using the user ubuntu, the home directory will be /user/ubuntu. When you don’t specify a directory name the listing becomes relative to your home directory.
Directory listing – local filesystem vs. HDFS
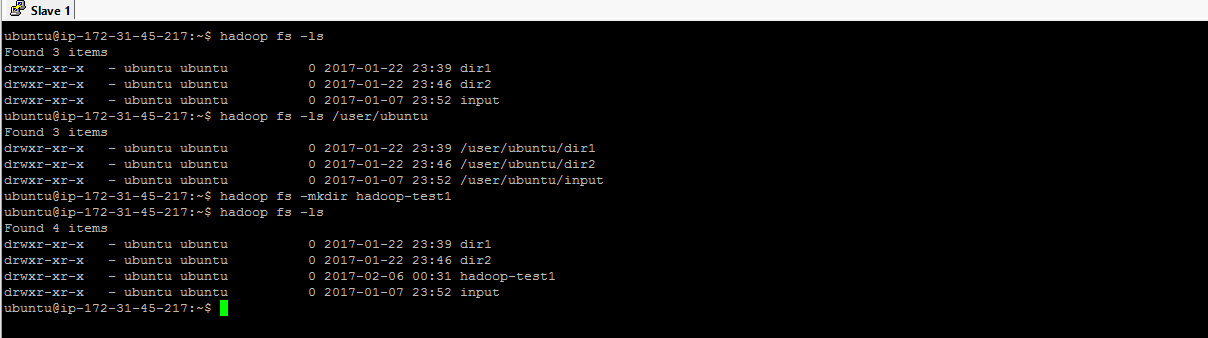
Here is the command to create a directory in HDFS – hadoop fs -mkdir hadoop-test1. Once the directory is created, lets do the listing and check out the directory in HDFS. Lets also do a local listing and when we do the local listing, we don’t see the directory that we created and that is exepected. Why?? because you created a directory in Hadoop Distributed filesystem and not on your local filesystem. So it is very clear that the view and content of HDFS will be vastly different from the local filesystem.
Copying files – to & from HDFS
To copy files from the local filesystem to HDFS, use copyFromLocal command and to copy files from HDFS to the local file sytem use copyToLocal command
copyFromLocal takes 2 parameters – 1st parameter is the source location of the file to be copied in the local filesystem and 2nd parameter is the destination location in HDFS where the file will be copied.
Now lets do the opposite – let’s bring a file from HDFS to local filesystem using the copyToLocal command. Again, this command takes 2 parameters and they are reveresed this time. The first parameter is location in HDFS andthe 2nd parameter is the current directory in the local filesystem.
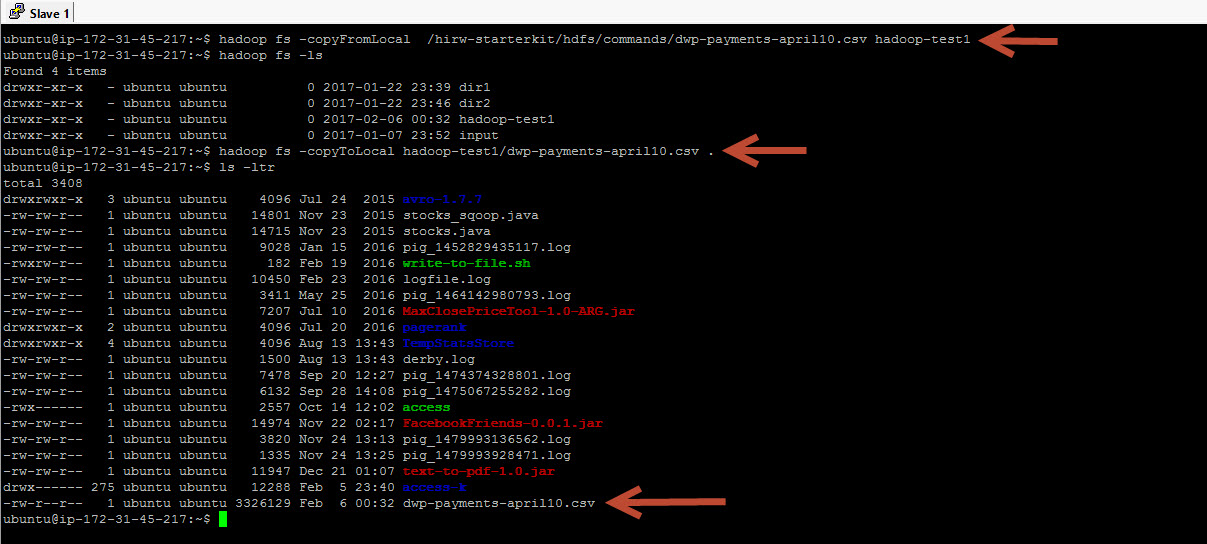
### LISTING ROOT DIRECTORY ### hadoop fs -ls / ### LISTING DEFAULT TO HOME DIRECTORY ### hadoop fs -ls hadoop fs -ls /user/hirwuser150430 ### CREATE A DIRECTORY IN HDFS ### hadoop fs -mkdir hadoop-test1 ### COPY FROM LOCAL FS TO HDFS ### hadoop fs -copyFromLocal /hirw-starterkit/hdfs/commands/dwp-payments-april10.csv hadoop-test1 ### COPY TO HDFS TO LOCAL FS ### hadoop fs -copyToLocal hadoop-test1/dwp-payments-april10.csv . hadoop fs -ls hadoop-test1
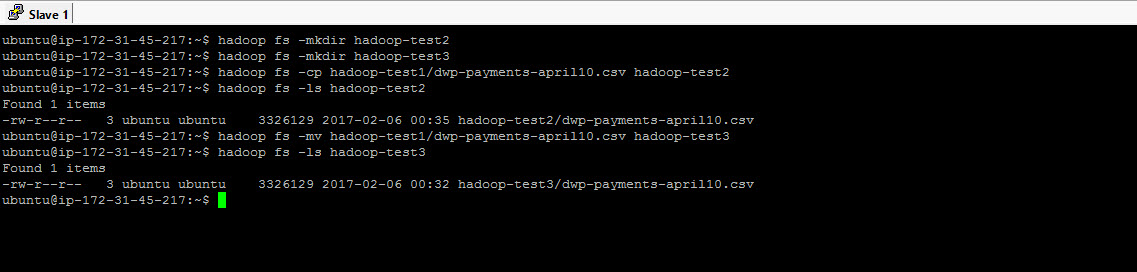
The next set of commands are very simple. We are going to create couple of folders in hdfs and copy and move files to and from the folders.
### CREATE 2 MORE DIRECTORIES ### hadoop fs -mkdir hadoop-test2 hadoop fs -mkdir hadoop-test3 ### COPY A FILE FROM ONE FOLDER TO ANOTHER ### hadoop fs -cp hadoop-test1/dwp-payments-april10.csv hadoop-test2 ### MOVE A FILE FROM ONE FOLDER TO ANOTHER ### hadoop fs -mv hadoop-test1/dwp-payments-april10.csv hadoop-test3
Replication factor & permissions
We talked about replication quite a bit in our previous post, lets see where we can find information about replication in HDFS.
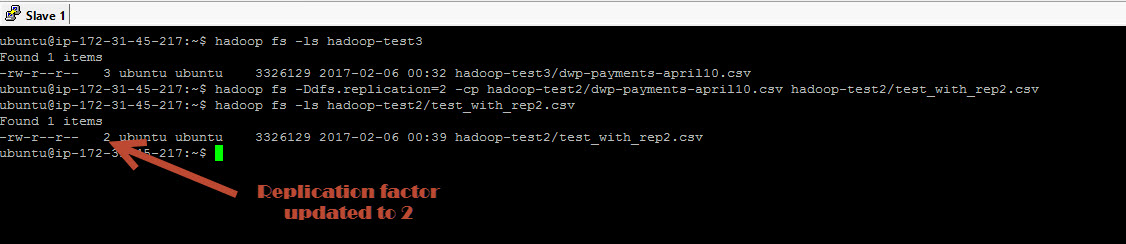
Simply do a listing on HDFS you see the number 3 (see screenshot) that is the replication factor of this file. This means, the file divided in to blocks and each block is replicated 3 times in the cluster. Replication factor is set to 3 by default but we can change the replication factor as we please using the dfs.replication property. Lets try to change the replication factor of a file to 2 frm 3.

### CHECK REPLICATION ### hadoop fs -ls hadoop-test3 ### CHANGE OR SET REPLICATION FACTOR ### hadoop fs -Ddfs.replication=2 -cp hadoop-test2/dwp-payments-april10.csv hadoop-test2/test_with_rep2.csv hadoop fs -ls hadoop-test2 hadoop fs -ls hadoop-test2/test_with_rep2.csv
Changing file permissions is done exactly as you would do in linux using chmod. The user who you are logged in as drives the permission in HDFS. I am logged in as ubuntu and any user I create, ubuntu will be the owner.
### CHANGING PERMISSIONS ### hadoop fs -chmod 777 hadoop-test2/test_with_rep2.csv

Blocks & FSCK
One of the important objective of this post is to understand how HDFS and Local filesystem co-exists. When we copy a file to HDFS, the file is divided in to blocks and the blocks are stored in individual nodes. HDFS has a global view of the file eventhough the file is spread across the nodes in the cluster. Where as the local filesystem has local view of the blocks. Many Hadoop learners fail to understand this and miss the Local filesystem’s involvement here.
So when you upload a file the individual blocks are stored by the local file sytem in each node but where? Why we don’t see them. Before we look at where the blocks are store. lets get a little more information about the file in HDFS.
fsck – filesystem check command is an excellent command and will get you more information about the files or folders in HDFS. You would need root prvileges to run this command. Lets try fsck on the stocks dataset that we have in the cluster. The dataset is about 1 GB in size so with a block size of 128 MB it is divided in to 8 blocks.
The replication factor of this file is 3. With fsck command, we will also see the information about the underreplicated blocks, that is blocks that are replicated less than 3 times or the configured replication factor for the file. Next we can find the list of blocks with block names and the location of the blocks. Next important information is the status. This file is listed as healthy. You can also see a more information about the blocks here.
### FILE SYSTEM CHECK - REQUIRES ADMIN PREVILEGES ### sudo -u hdfs hdfs fsck /user/hirwuser150430/hadoop-test2 -files -blocks -locations sudo -u hdfs hdfs fsck /user/hirwuser150430/hadoop-test3 -files -blocks -locations sudo -u hdfs hdfs fsck /user/ubuntu/input/yelp/yelp_academic_dataset_review.json -files -blocks -locations
Blocks location
So now we know information about the blocks but where these blocks are physically stored ?
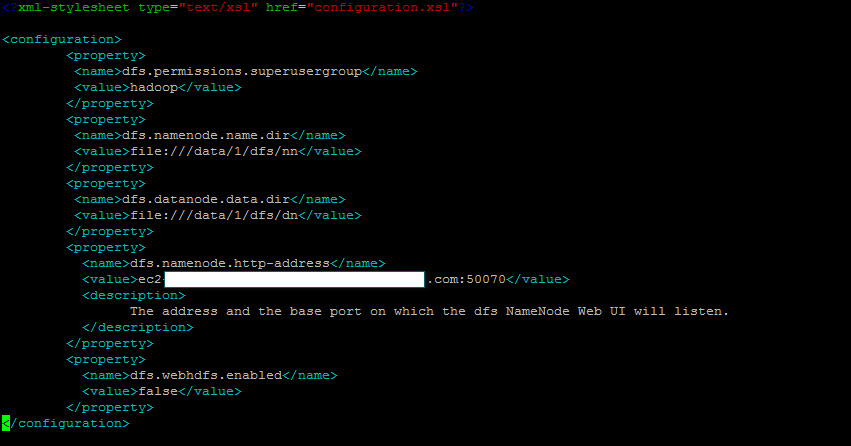
It is stored in the location defined in hdfs-site.xml file. hdfs-site.xml is an important file which lists the properties important to configure HDFS. this file is usually defined by your hadoop administrator during cluster set up. In our cluster you can find this file under /etc/hadoop/conf/. dfs.datanode.data.dir property defines the location where the block will be physically located in the local filesystem.
When we go to the folder mentioned in dfs.datanode.data.dir property, we can see the blocks.
So far we looked at some very important HDFS commands which are useful to work with the cluster. We also understand the key differences between HDFS and the local filesystem. As you can see storing a file in HDFS is a lot more involved internally. That is, a file has to be divided in to blocks and the blocks has to be store in various nodes. Plus it has to be replicated and when a user asks for a file, HDFS should know how to construct the files from the blocks, so which mean it should keep track of the block and that’s a lot of work.
So some process or processes has to be involved to perform all this work to keep HDFS functional. To understand what really happens behind the scenes we need to understand the components and architecture of HDFS. So that’s is what we will see in the next post.

