
Hadoop Starter Kit – Tutorial
February 16, 2017Dissecting MapReduce Components
February 23, 2017Introduction to MapReduce
By now you are quite familiar with HDFS, if you are not to back to the beginning of this tutorial and follow links for HDFS. It is now time to learn about MapReduce.
You can get access to our free Hadoop cluster to try the commands in this post. Before you go on reading this post, please note that this post is from our free course named Hadoop Starter Kit. It is a free introductory course on Hadoop and it is 100% free. Click here to enroll to Hadoop Starter Kit. You will also get free access to our 3 node Hadoop cluster hosted on Amazon Web Services (AWS) – also free !
So in this post we are going to learn about the basic concepts of MapReduce but we are not going to bore you with Word Count problem. We are going to learn the MapReduce concept using a fun example. Alright, let’s pick a State – Califoria. Imagine for a second, the governor of Californina comes up to you and made you the head of census bureau for the state of California and you are tasked with finding the population of all cities in California. You have all the resources you want but you have only 4 months to finish the task.
Solving the census problem
Think about this for a second, how would you proceed with this task? Just remember you can have all the resources you want. How would you approach this problem?
Calculating the population of all cities in a big state like California is not an easy task for any one person. So the sensible thing to do is divide the state by city and make individuals incharge of each city to calculate the population of each city he/she is incharge of. Just for illustration purpose, lets focus on only 3 cities – San Fransisco, San JOSE, and LA. Person 1 will be incharge of SFO, Person 2 will be incharge of San Jose and Person 3 will be incharge of LA.
So far good. You have divided Californina in to cities and each city is assigned to a person and he is responsible for finding the population of the assigned city. You now need to give instructions to each person on what they have to do. You ask each person to go to a home, knock on the door and when someone answers the door. ask how many people live in the home and note it down.
You give them specific instruction on what each person should note down. You are instructing each one to note down the city they are responsible for and the number of people live in the home. Then the person has to go to the next home and repeat the same process until he covers all homes in the assigned city. So for a person who covers SFO, he goes to the first home, there are 5 people in the home, so he will note down “SFO 5”. 3 people are living in the 2nd home and he will note down “SFO 3”. You get the idea…
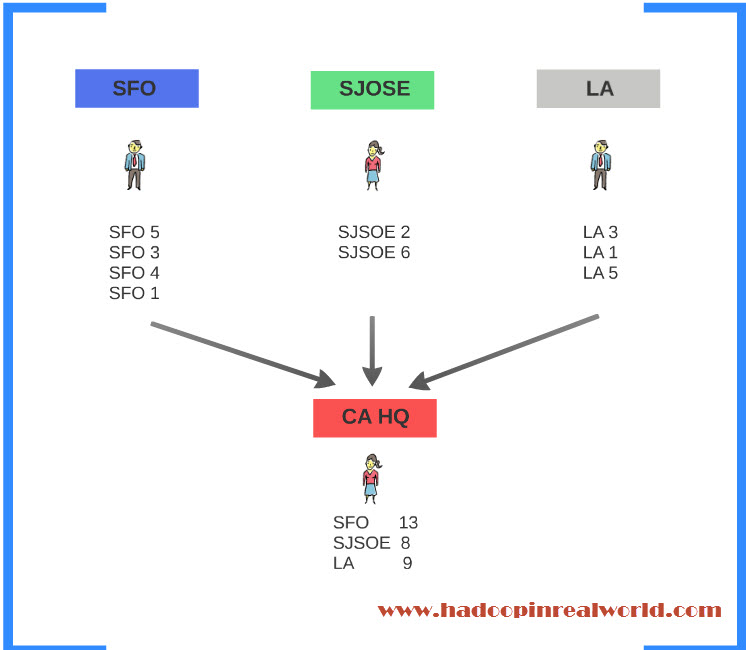
It is a classic divide and conquer approach. Same instructions will be carried out by everyone involved. Person 2 will do for San Jose and Person 3 will do for LA. When each person is done with their assigned city you will ask them to submit their result to the state’s head quarters. You will have a person in the head quarters to receive the results from all cities and aggregate them by city to come up with population of each city for the entire state.
Very simple process right. 4 months in, with this strategy you were able to calculate the population of California. The governor who gave you the job is very happy with your performance. Next year around you are asked to do the same job. Again, you have all the resources you want but this time you have 2 months to finish the task. What would you do?
Remember, you have all the resources you want. So you would simply double the number of people to perform the tasks. You will divide SFO in to 2 divisions and add one person to each division. You will do the same thing for San Jose and same for LA. You can also do the same thing at the head quarters. Let’s divide the head quarters in to two. CA HQ1 and CA HQ2 and one person to each division. Perfect!
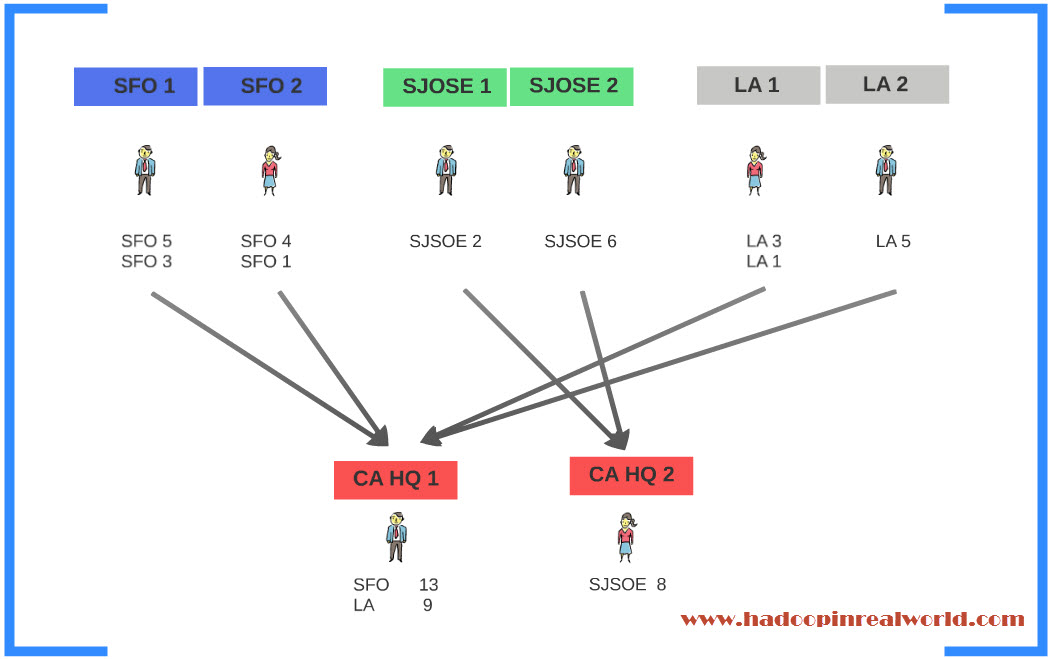
With twice as much people you can finsh the task in half the time. But there is one small problem. You want the census takers for SFO – SFO1 and SFO2 send their results to either CA HQ1 or CA HQ2. You don’t want SFO1 sending their results to CA HQ1 and SFO2 sending their results to CA HQ2 because this would result in population count for SFO divided between Head quarters 1 and 2. This is not ideal because we want the consolidated population count by city, not partial counts. So what can we do?
Simple, we can instruct census takers in SFO1 and 2 to send to thier result to either headquarters 1 or headquarters 2. Similarly we should instruct census takers for San Jose and LA; they should send to either HQ 1 or HQ 2. Problem solved!
You try with this model and again you did it. You were able to complete the census calculation in 2 months. If next year, if you were asked to do the same thing in 1 month, you know exactly what to do. You can simply double the resources and apply your model and it will work like a charm. You now have a good enough model. not only the model works but it can also scale.
That’s it. the Model you have is called Map Reduce.
Introducing MapReduce & its’ phases
MapReduce is a programming model for distributed computing. Tt is not a programming language, it is a model which you can use to process huge datasets in a distributed fashion. Now lets look at the phases involved in MapReduce.
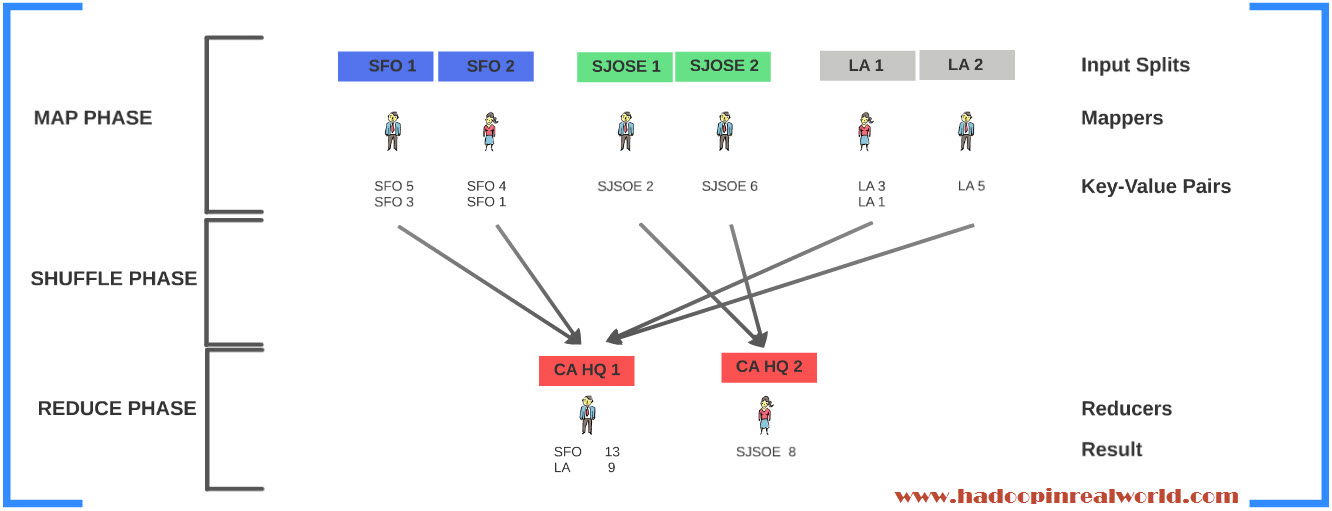
The phase where individuals calculate the population of their assigned city or part of city is called the Map Phase. The individual person involved in the actual calculation is called the Mapper and the city or part of the city he is working with is known as the Input Split. The output from each Mapper is a Key Value pair.
The phase where you aggregate the intermediate results from each city or Mappers in the Head Quarters is called the reduce phase. The individuals who work in the head quarters are known as the reducers because they reduce or consolidate the output from many different mappers. Each reducer will produce a result set.
The phase in which the values from many different mappers are copied or transfered to the reducers is known as the shuffle phase. the shuffle phase comes in between Map and Reduce phase.
Map Phase, Shuffle Phase and Reduce Phase are the 3 phases of MapReduce.
We will look closer in to each phase in the next post. Where will talk about more entities like combiner, partitioner etc. Once we understand the each phases in detail we will be able to write a MapReduce program in Java. One step at a time.
