
Dissecting MapReduce Components
February 23, 2017Dissecting MapReduce Program (Part 2)
March 2, 2017Dissecting MapReduce Program (Part 1)
From the previous post, we now we have a very good idea about the phases involved in MapReduce. We have a very good conceptual understanding of what is a Mapper, Reducer, Combiner etc. Now to the fun part. lets go ahead and write a MapReduce program in Java to calculate the Maximum closing price by the stock symbol from stocks dataset.
Before you go on reading this post, please note that this post is from our free course named Hadoop Starter Kit. It is a free introductory course on Hadoop and it is 100% free. Click here to enroll to Hadoop Starter Kit. You will also get free access to our 3 node Hadoop cluster hosted on Amazon Web Services (AWS) – also free !
Here is the game plan. we are going to write 3 programs – Mapper, Reducer and a Driver program. We know what a Mapper and what is a Reducer but what is a Driver program ? So let’s start with that. A driver program will provide all the needed information and bring all the needed information together to Submit a MapReduce job. We will see each one in detail in this post.
package com.hirw.maxcloseprice;
/**
* MaxClosePrice.java
* www.hadoopinrealworld.com
* This is a driver program to calculate Max Close Price from stock dataset using MapReduce
*/
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class MaxClosePrice {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxClosePrice <input path> <output path>");
System.exit(-1);
}
//Define MapReduce job
Job job = new Job();
job.setJarByClass(MaxClosePrice.class);
job.setJobName("MaxClosePrice");
//Set input and output locations
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Set Input and Output formats
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//Set Mapper and Reduce classes
job.setMapperClass(MaxClosePriceMapper.class);
job.setReducerClass(MaxClosePriceReducer.class);
//Combiner (optional)
job.setCombinerClass(MaxClosePriceReducer.class);
//Output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//Submit job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Job object refers to a MapReduce job. Instantiate a new object and give a name to the job. When we run this job on a Hadoop cluster, we will package the code in to a Jar and Hadoop will distribute the jar across all the nodes in the cluster. setJarByClass method takes in the class and Hadoop uses this class to locate the Jar file. In the next few lines you would set the input path where you can find the input dataset and the output path where you want your reducers to write the output.Also you have to specify the format of your input and output dataset.
Let’s talk about InputFormat first. InputFormat is responsible 3 main tasks –
First, it Validate inputs, meaning make sure the dataset actually exists in the location that you specified.
Next, Split-up the input file(s) into logical InputSplit(s), each of which is then assigned to an individual Mapper.
Finally and this is important, InputFormat provides. RecordReader implementation to extract input records from the logical InputSplit for processing by the Mapper.
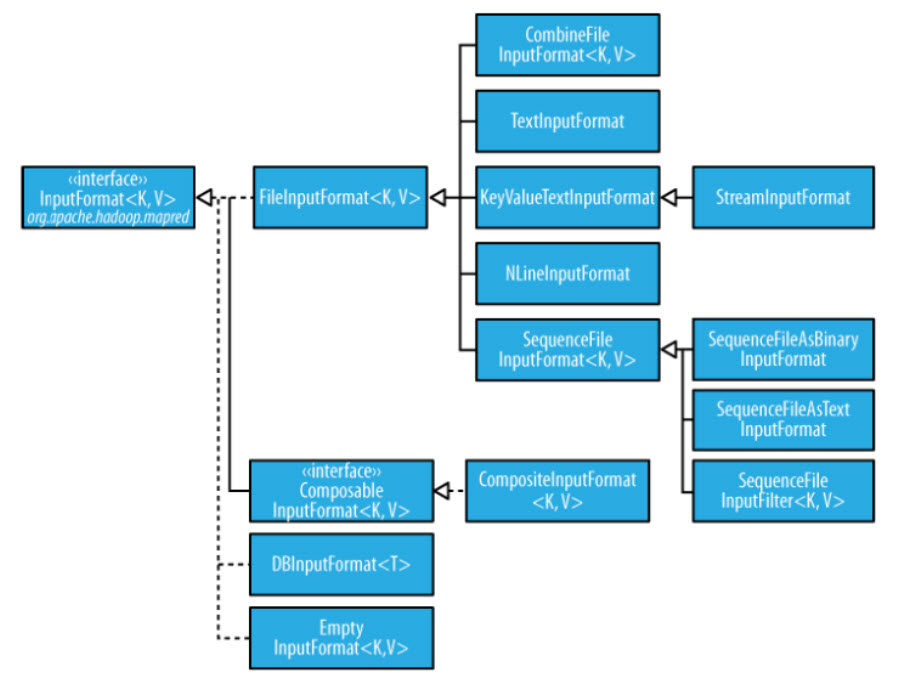
In our case, our stocks dataset is of Text format and each line in the dataset is a record. So we will use TextInputFormat. Hadoop provides several other InputFormats each designed for a specific purpose. for eg. if your dataset has binary key value pairs you can use Sequence File InputFormat. There are several important file formats in use like AVRO, Sequence, RCRile etc. infact due to its importance, we have a separate chapter in our Hadoop Developer In Real World course dedicated to file formats. Further more we will also look at implementing a custom File format in the course.
Similar to InputFormat, OutputFormat validate output specifications and has RecordWriter implementation to be used to write out the output files of the job. Hadoop comes with several OutputFormat implementations, infact for every InputFormat you can find a corresponding OutputFormat and also you can write custom implementations of OutputFormat.

Next set the Mapper and Reducer classes for this MapReduce job. Our Mapper is MaxClosePriceMapper and our Reducer is MaxClosePriceReducer. Also set the output key and the value types for both your Mapper and Reducer. The key is of type Text and value is of type FloatWritable.
These types look new doesn’t it? Yes they are new. There are writable wrappers in Hadoop for all major Java primitive types. For example, the Writable implemenation for int is IntWritable. for float is FloatWritable, for boolean is BooleanWritable and for String it is Text. But why new datatypes? when we already have well defined datatypes in Java?
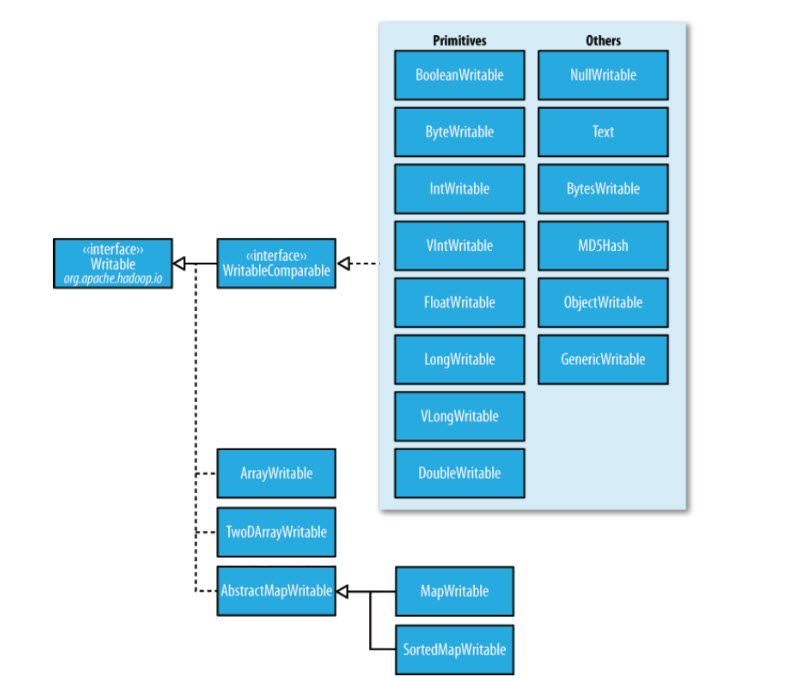
Writables are used when ever there is a need to transfer data between tasks. That is when the data is given as input and output to and from the mapper. They are used also when the data is given as input and output to and from the reducer. As you know Hadoop is a distributed computing framework. which means you will have Mappers and Reducers distributed in many different nodes and this mean you will have a lot of data being transferred between nodes. So when there is a need to transfer data over the network between nodes the objects must be turned in to byte stream and this process as we know is called serialization.
As you can imagine, Hadoop is designed to process is million and billions of records so there is a lot of data transferred over the network and hence Serialization should be fast, compact and effective. Authors of Hadoop felt the Java’s out of the box serailzation was not that effective in terms of speed and size. Here are couple of reasons why they felt so.
Java serialization writes the class name of each object which is being serialized to the byte stream. This is to know the object’s type so that we will be able to deserialize the object from the byte stream. Every subsequent instance of the class should have a reference to the first occurrence of the class name which this clearly takes up space. This reference result in two problems. first one is space and hence it is not compact. second problem is the reference handles introduce a problem during sorting records in a serialized stream, since only the first record will have the class name and must be given special care.

So Writables was introduced to make the Serialization fast and compact. How though? By simply not writing the class name to the stream. Then how would you know the type during deserialization? The assumption is that the client always knows the type and this is usually true.
There is one more benefit of using Writables as opposed to regular Java types. With standard Java types, when the objects are reconstructed from a byte stream during deserialization process, a new instance for each object has to be created. Where as with writables, the same object can be reused which improves processing efficiency and speed.
In the Hadoop Developer In Real World course look in to how to write Custom Writables when we look in to solving the common friends problem that we see in social sites like Facebook for instance. It’s an interesting project !
Wait for completion method submits the job and also waits for it to finish. set the boolean argument to true to so that you can see the progress of the job in the console. Let’s pause our post here. In the next post we will look at the Mapper and Reducer programs in detail and we will also execute the MapReduce program in our Hadoop cluser.
