
Introduction to MapReduce
February 20, 2017Dissecting MapReduce Program (Part 1)
February 27, 2017Dissecting MapReduce Components
In the last post we looked at different Phases of MapReduce. In this post we will take a real example and walk through the process involved working with MapReduce.
Before you go on reading this post, please note that this post is from our free course named Hadoop Starter Kit. It is a free introductory course on Hadoop and it is 100% free. Click here to enroll to Hadoop Starter Kit. You will also get free access to our 3 node Hadoop cluster hosted on Amazon Web Services (AWS) – also free !
Here is the problem we like to solve today. We have a dataset with information about several fictitious stocks symbol. Each line in the dataset we have information about a stock symbol for a day… information like the opening price, closing price, high, low, volume and adjusted closing price for a given day.
Dataset & problem description
ABCSE,B7J,2010-01-20,8.93,9.09,8.93,9.09,119300,9.09 ABCSE,B7J,2010-01-19,8.99,9.04,8.91,9.02,132300,9.02 ABCSE,B7J,2010-01-15,8.98,9.00,8.90,8.99,78000,8.99 ABCSE,B7J,2010-01-14,9.03,9.03,8.93,9.01,142700,9.01 ABCSE,B7J,2010-01-13,8.96,9.00,8.92,8.98,101600,8.98 ABCSE,B7J,2010-01-12,8.91,8.95,8.86,8.91,70600,8.91 ABCSE,B7J,2010-01-11,8.99,9.00,8.95,8.97,159500,8.97 ABCSE,B7J,2010-01-08,8.90,8.95,8.88,8.94,153100,8.94 ABCSE,B7J,2010-01-07,8.91,8.94,8.88,8.94,120700,8.94
Lets pick a record in this dataset, in this record we have information for symbol. B7J. for date 2010-01-20 and we have the opening price, high, low close price, volume etc.
The size of this data is slightly over 400 MB. Not too big but good enough for our experimentation. Now lets talk about the problem we would like to solve with this dataset. For every stock symbol in the dataset we would like to find out its maximum closing price across several days. Simple use case right?
Simple algorithm
Now think about this problem for a second. forget about MapReduce and Hadoop. How would you solve this problem? Just think about the the algorithm.

We will read a line, get the symbol and closing price from the line. Then we need to check, is this closing price greater than the closing price we have for the symbol. If not go process the next line. If it is the greater than the closing price, save the closing price as the maximum closing price for that symbol and move on to the next record in the dataset. If you reached the end of the file, print the results.
Now the problem with this approach is that there is no parallelization. So if you have a huge dataset you will have extremely long computation time which is not ideal. Now lets see how we have work out the same problem in the MapReduce world.
From the last post we got introduced to the phases of MapReduce. So we will take this problem and go over each phase and see the technical details involved in the Map Phase, Reduce Phase and the Shuffle phase. Lets first talk about the Map Phase.
The central idea behind MapReduce is distributed processing. So the first thing to do is divide the dataset in to chunks and you have separate process working on the dataset on every chunk of data. Lets assign some technical Jargons now the chunks are called input splits and the process working on the chunks are called Mappers.

Every mapper execute the same set of code and for each record they process in the input split, they could emit a key value pair.
Block vs. InputSplit
First what is an Input Split?
How many of you think Input Split is same as the Block??
InputSplit is not same as the block. A block is a hard division of data at the block size. So if the block size in the cluster is 128 MB. Each block for the dataset will be 128 MB except for the last block which could be less than the block size if the file size is not entierly divisible by the block size. Make sense?
Since block is a hard cut at the block size block can end even before a record ends. Consider this, your block size in your cluster is 128 MB. Each record is your file is about 100 Mb. Yes, imagine huge records. So the first record will pefectly fit in the block no problem since the record size 100 MB is well with in the block size which is 128 MB. However the 2nd record can not fit in the block. So the record number 2 will start in block 1 and will end in block 2.

If you assign a mapper to a block 1, in this case, the Mapper can not process Record 2 because block 1 does not have the complete record 2. That is exactly the problem InputSplit solves. In this case Input Split 1 will have both record 1 and record 2. Input Split 2 does not start with Record 2 since Record 2 is already included in the Input Split 1. So Input Split 2 will have only record 3. As you can see record 3 is divided between Block 2 and 3. Input Split is not physical chunks of Data. It is a Java class with pointers to start and end locations with in blocks.
So when Mapper tries to read the data it clearly knows where to start and where to end. The start location of an input split can start in a block and end in another block. So that is why we have a concept of Input Split. Input Split respect logical record boundary. During MapReduce execution Hadoop scans through the blocks and create InputSplits which respects the record boundaries. Now that we understand the input to each Mapper lets talk about the Mapper itself.
Map Phase
Mapper is a Java program which is invoked by the Hadoop framework once for every record in the Input Split so if you have 100 records in a Input Split the Mapper processing the split will be executed 100 times. How many mappers do you think Hadoop will create to process a dataset?
That is entirely dependent on the number of Input Splits. If there are 10 Input Splits there will be 10 mappers. If there are 100 input splits there will be 100 mappers. So a mapper is invoked for once every single record in the input split. Then what? The output of the Mapper should be a key value pair.
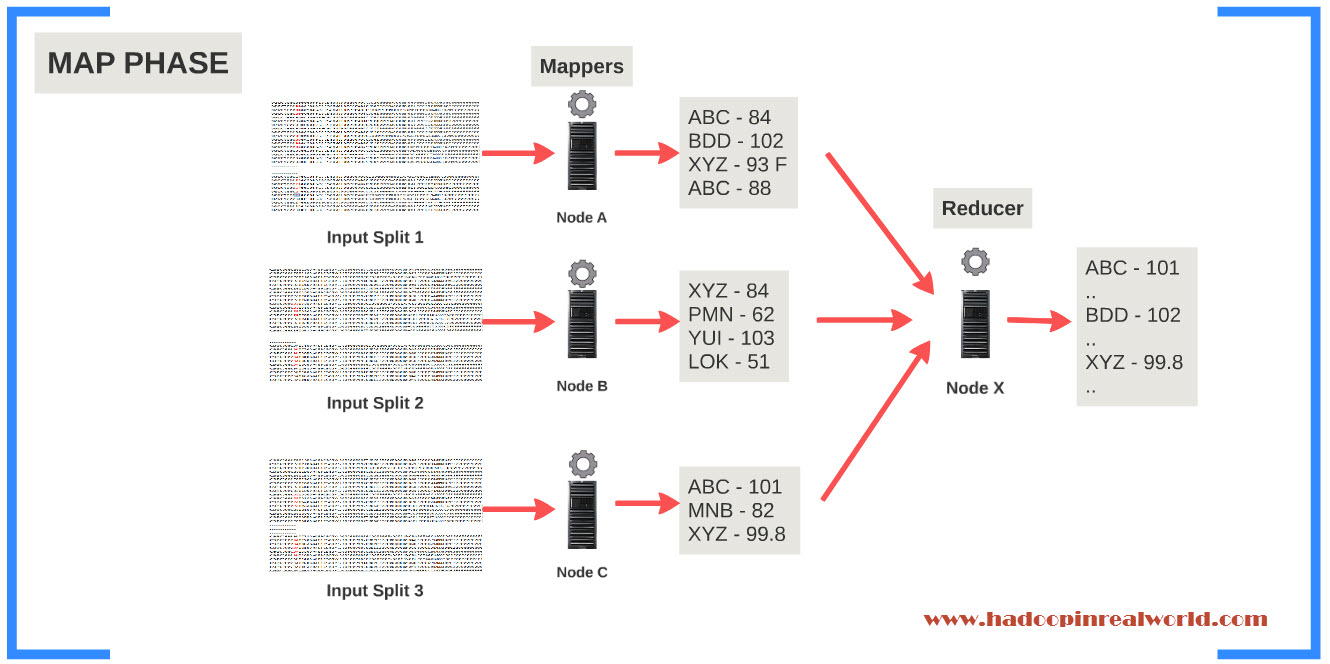
In our sample stock dataset, every line is a record for us and we need to parse the record to get the stock symbol and the closing price. So stock symbol and closing price becomes the output. Symbol is the key and closing price is the value.
How do you decide what should be the key and what should be symbol?
Reduce Phase
Lets look at the Reduce Phase. That will give us an answer. The reducers work on the output of the Mappers. The ouput of the individual Mappers are grouped by Key in our case the stock symbol and passed to the reducer. Reduce will receive a Key and a List of values for input. The keys will be grouped and lets say our dataset has stock information about 10 stocks symbols and 100 records for each symbol. That is 1000 records.

So you will get 1000 key value pairs from all the Mappers combined. When processing a record you can also decide not to output a key value pair for that record. For eg. The record could be bad record in that case you can’t output a record. Then the reducer will receive 10 records to process – one record for each stock symbol. since we only have information about 10 stocks.
Each record for the reducer will have a symbol and a list of closing prices for values. That is all you need to calculate the maximum closing price of each symbol correct? The work of the reducer becomes very simple. It reads the key and calculate the maximum closing price from the list of closing prices for that symbol and output the result.
So going back to our question – How do you decide what should be the key and what should be symbol? Whenever in doubt think about what needs to be reduced. We know if the reducer has the stock symbol and list of closing prices for the given stock symbol we can arrive at a solution. Also we want the reducer to be called once per stock symbol and that is why we made the symbol as the key in Mapper’s output and Closing Price became the value.
One more question – we know the number of mappers equals to the input splits and not controlled by the user. What about the number of reducers?
The number of reducers can be set by the user. You can even have a MapReduce job with no reducers. Lets say your dataset is divided in to 100 splits which means 100 Mappers. Now if you have only one reducer to process all the output from 100 Mappers, in some cases it might be O.K. but you might run in to performance bottleneck at the Reduce phase. So if you are dealing with large amount of data in the reduce phase, it is advisable to have more than one reducer.
That is the Reduce Phase. How did the output of individual Mappers got the reducer grouped by symbols? The magic happens in the Shuffle Phase. Shuffle Phase is a key component in MapReduce. The process in which the Map Output is transferred to the Reducers is known as the Shuffle. Let’s now walk through the Shuffle Phase in detail.
Shuffle Phase
Lets say in our MapReduce job we decided to use 3 reducers. Lets say you have data for Apple in the stock dataset and we have 10 input splits to process, which means we will need 10 mappers. we can have records for apple in more than one input split and let’s assume the records for apple is spread out in all 10 input splits.
This means that each Mapper will produce Key Value pairs for Apple in its output. When you have more than one reducer you don’t want the Key Value pairs for Apple to spread out between the 3 reducers. That will be bad for our use case because we won’t be able to calculate a consolidated Max closing price for apple.
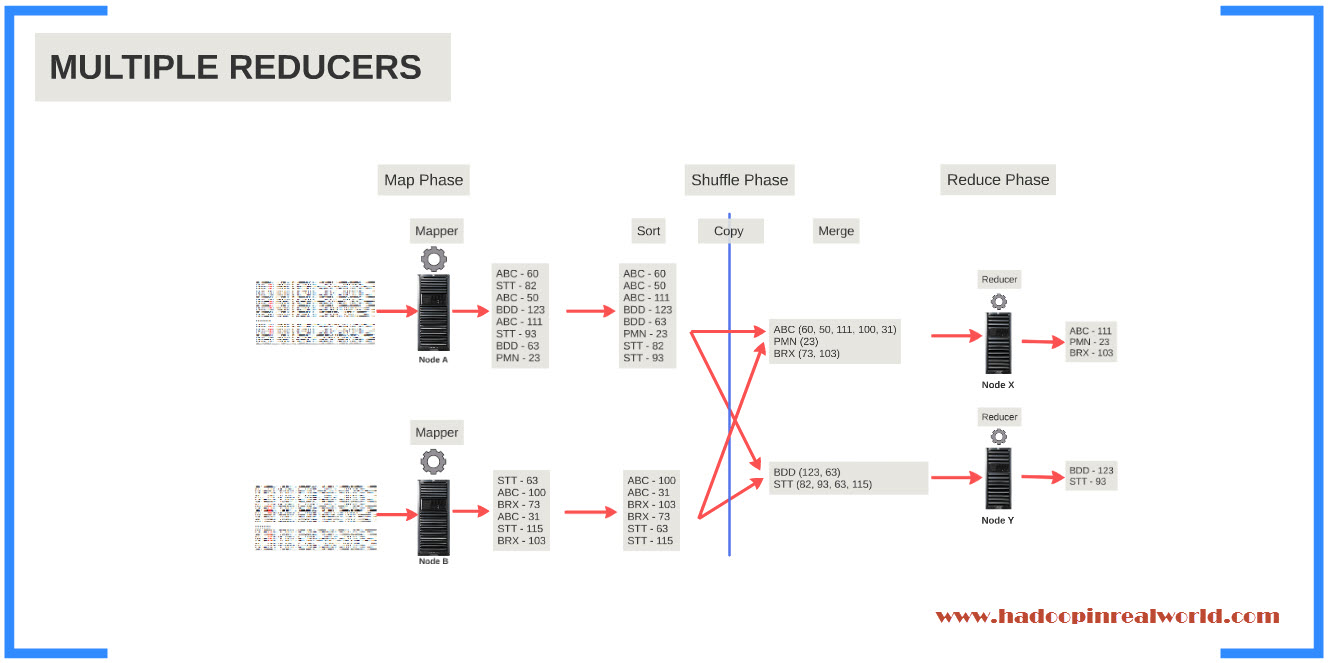
So we want all key value pairs of Apple to go to one reduce. In other words, we want each key or symbol in our case to be assigned to a reducer and stick to it. In the Map Phase each key is assigned to Partition, so if you have 3 reducers you will have 3 partitions. And each key is assigned to a Partition by a class called Partitioner. So if the Partitioner decides that any key value pair with Apple as Key should go to Partition 1 all the key value pairs with Apple as key will go to the Partition 1. Each Partition will be assigned to a Reducer. That is, partition 1 will be assigned to Reducer 1, partition 2 will be assigned to Reducer 2 etc.
It is key to understand that this paritioning happens across all the Mappers in the Map phase. Hadoop framework guarantee that input to the reducers is sorted by key and so once the keys are assigned to right partition the key value pairs in the partition are sorted by key. Once the keys are sorted. we are now ready to copy each partition to the appropriate reducers and this is known as the copy phase.
You have to understand that data for Partition 1 for instance can come from many mappers so in the Reduce phase the partitions have to merged together maintaining the sort ordering by key. Even though the intense sorting happened at the Map phase, the merging task in the reduce side is called the sort phase. Once the reducers have received all the partitions from all the mappers and the partitions are merged the reducer will perform the actual reduce operation.
Lets summarize the shuffle phase. Each mapper will process all the records in the input splits and will output a key value pair for each record. If you look at the output we have symbol for key and closing price as value. We have ABC 60, STT 82. Same with all the other mappers too. You may also note that the symbols in Mapper 1 can also found in Mapper 1. Look at the symbol STT for instance.
Then in the shuffle phase with in each mapper the key value pairs will be assigned to a partition. With in each partition the key value pairs will be sorted by key. As you can see in the slide the ouput key value pairs are nicely sorted by key. Then the key value pairs from each mapper will be copied over to the reduce phase to the appropriate reducers. At each reducer the the key value pairs coming from different mappers will be merged maintainng the sort order.
There are 2 things to note in the slide. First is the the symbols are unique to each reducer. Meaning eventhough records for a given symbol were spread across in multiple mappers all key value pairs for a given symbol will be sent to one reducer. Second is the sort order by key is maintained.
Then the job for the reducer is simple. The reducer 1 will run 3 times once for each symbol and reducer 2 will run 2 times once for each symbol. Each run will output the symbol and its maximum closing price. That is the end to end process.
Combiner
We could have an optional Combiner at the Map Phase. Combiners can be used to reduce the amount of data that is sent to the reduce phase. In our example there is no reason to send all the closing prices for each symbol from each mapper. For eg. In mapper 1 we have 3 records for ABC so we have 3 closing prices for ABC – 60, 50 111. Since we are calculating the maximum closing price we don’t have the send the key value pairs with closing price 50 and 60. Since they are less than 111. So all we need is to send the key value pair with closing price 111 for symbol ABC.

If you think about it. Combiner is like mini reducer that is executed at the Map Phase. Combiners can be very helpful to reduce the load on the reduce side since you are reducing the amount of data that are being sent to the reducers, there by increasing the performance. Combiner is optional.
So to summarize in this post we talked about the internals of Map, Shuffle and Reduce phases and finally we looked at the benefit of using a combiner. In the next post we will dissect a MapReduce program written in Java and understand the program in great detail.
